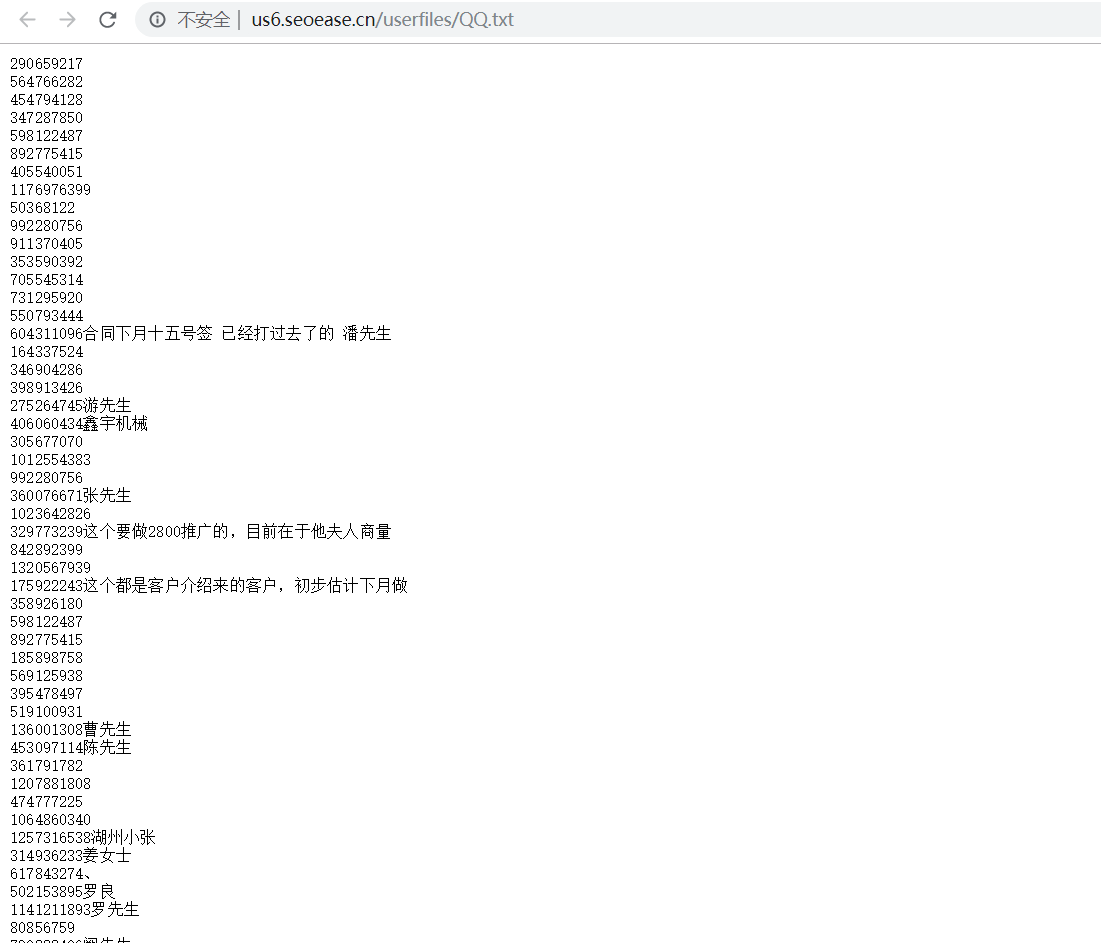
-d: Domain to search or company name -b: data source: baidu, bing, bingapi, censys, crtsh, dogpile, google, google-certificates, googleCSE, googleplus, google-profiles, hunter, linkedin, netcraft, pgp, threatcrowd, twitter, vhost, virustotal, yahoo, all -g: use Google dorking instead of normal Google search -s: start in result number X (default: 0) -v: verify host name via DNS resolution and search for virtual hosts -f: save the results into an HTML and XML file (both) -n: perform a DNS reverse query on all ranges discovered -c: perform a DNS brute force for the domain name -t: perform a DNS TLD expansion discovery -e: use this DNS server -p: port scan the detected hosts and check for Takeovers (80,443,22,21,8080) -l: limit the number of results to work with(Bing goes from 50 to 50 results, Google 100 to 100, and PGP doesn't use this option) -h: use SHODAN database to query discovered hosts Examples: theharvester -d microsoft.com -l 500 -b google -f myresults.html theharvester -d microsoft.com -b pgp, virustotal theharvester -d microsoft -l 200 -b linkedin theharvester -d microsoft.com -l 200 -g -b google theharvester -d apple.com -b googleCSE -l 500 -s 300 theharvester -d cornell.edu -l 100 -b bing -h
-d: domain to search -t: filetype to download (pdf,doc,xls,ppt,odp,ods,docx,xlsx,pptx) //可以下文件 -l: limit of results to search (default 200) -h: work with documents in directory (use "yes"forlocal analysis) -n: limit of files to download -o: working directory (location to save downloaded files) -f: output file

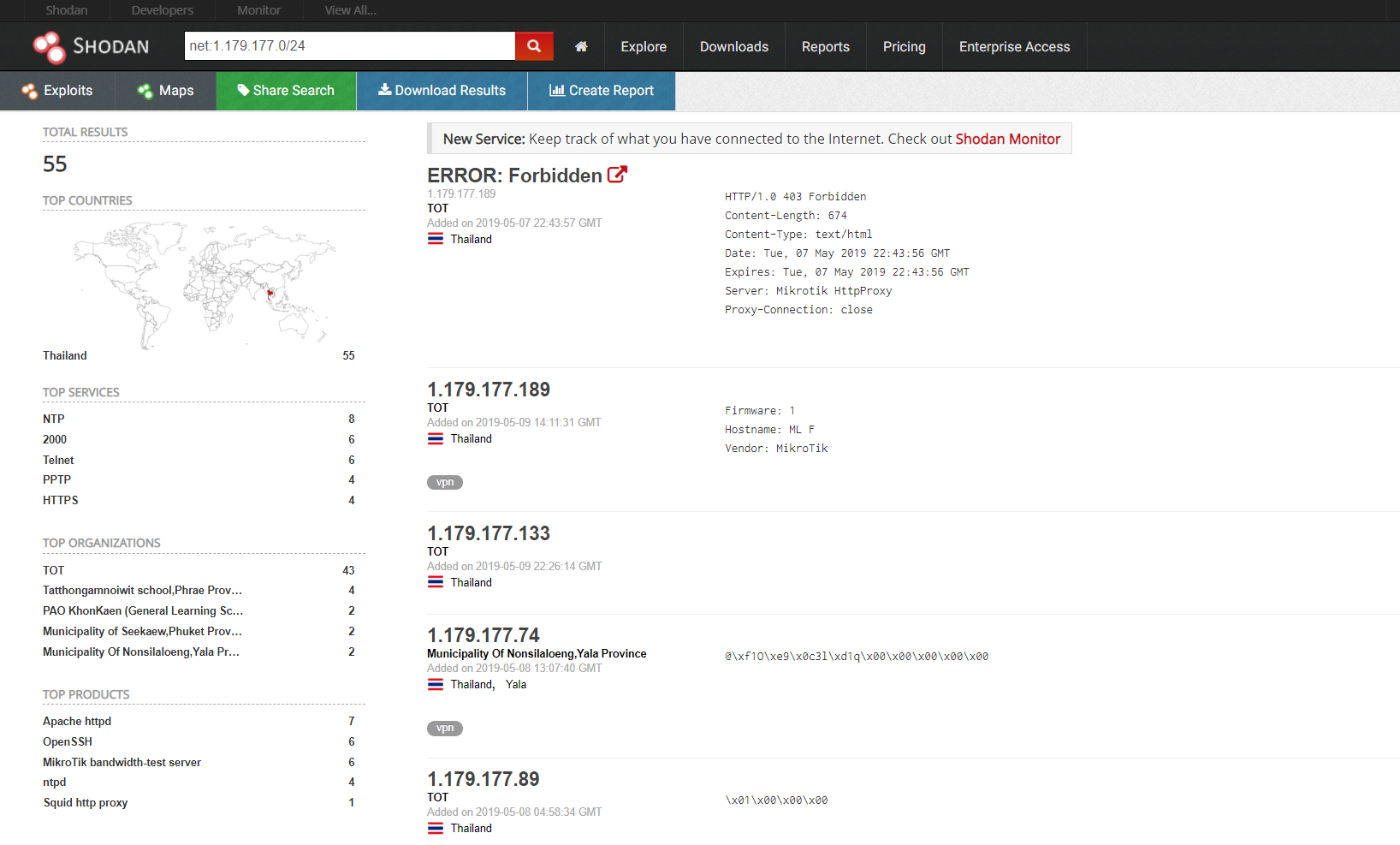
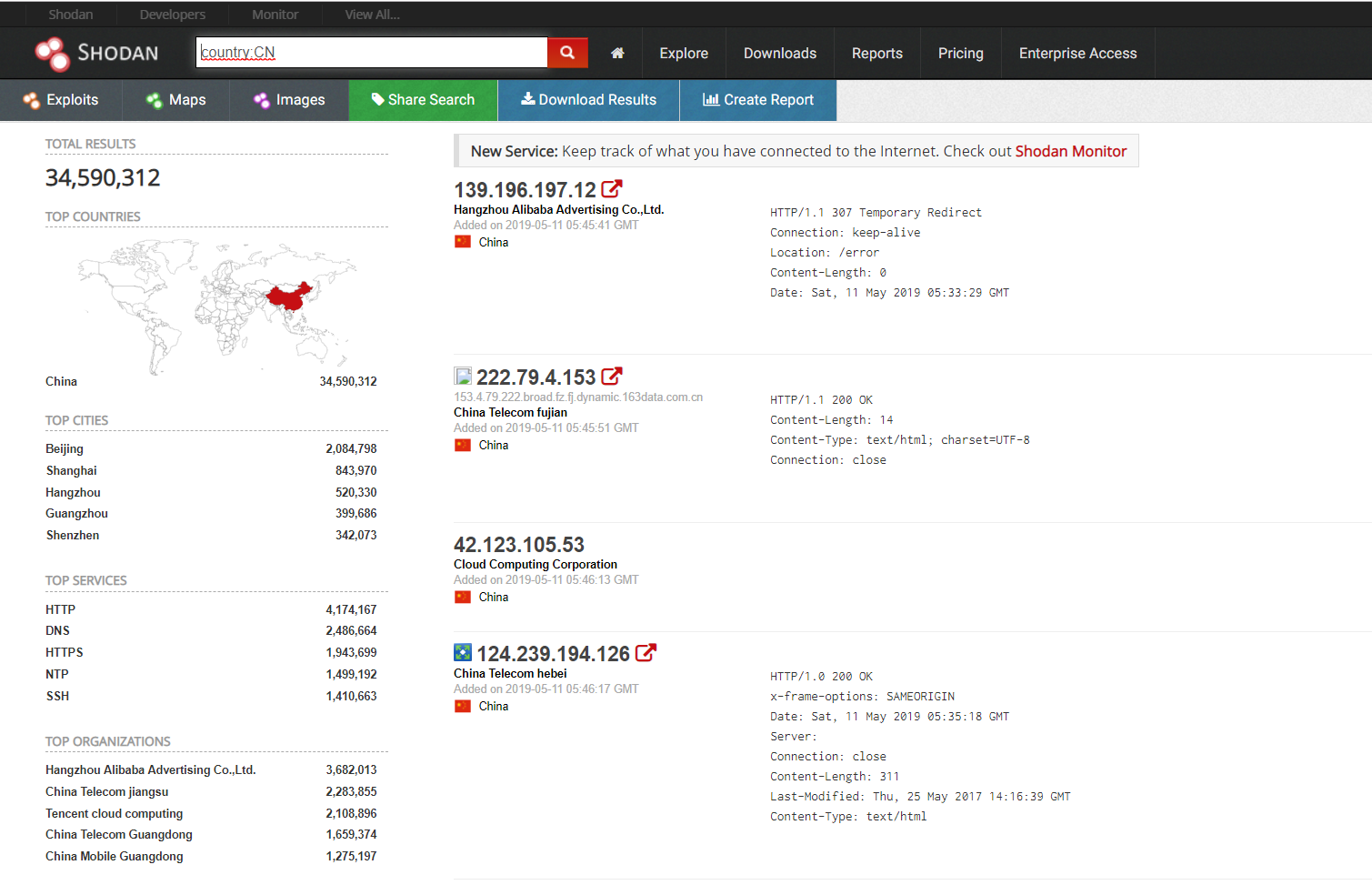
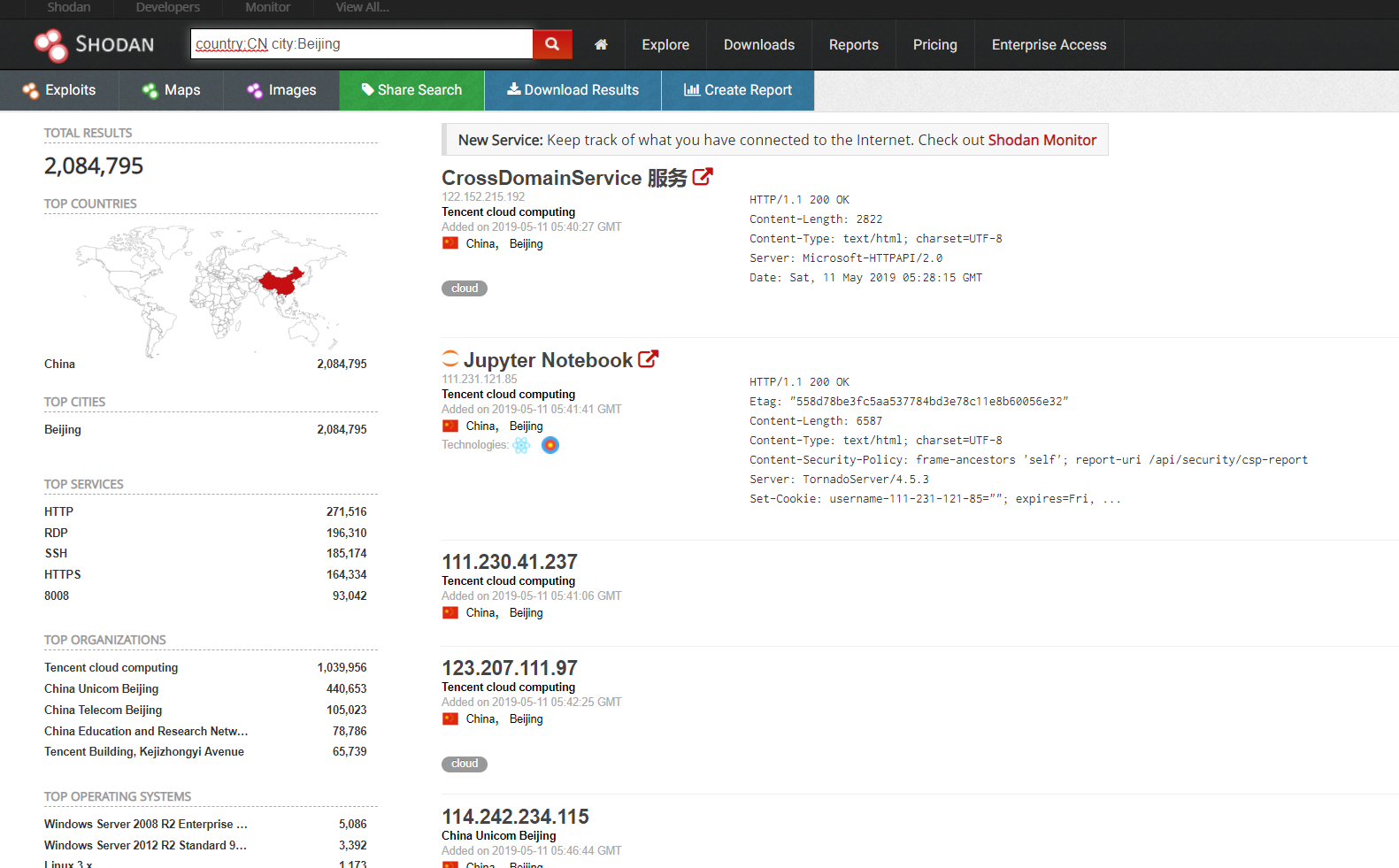
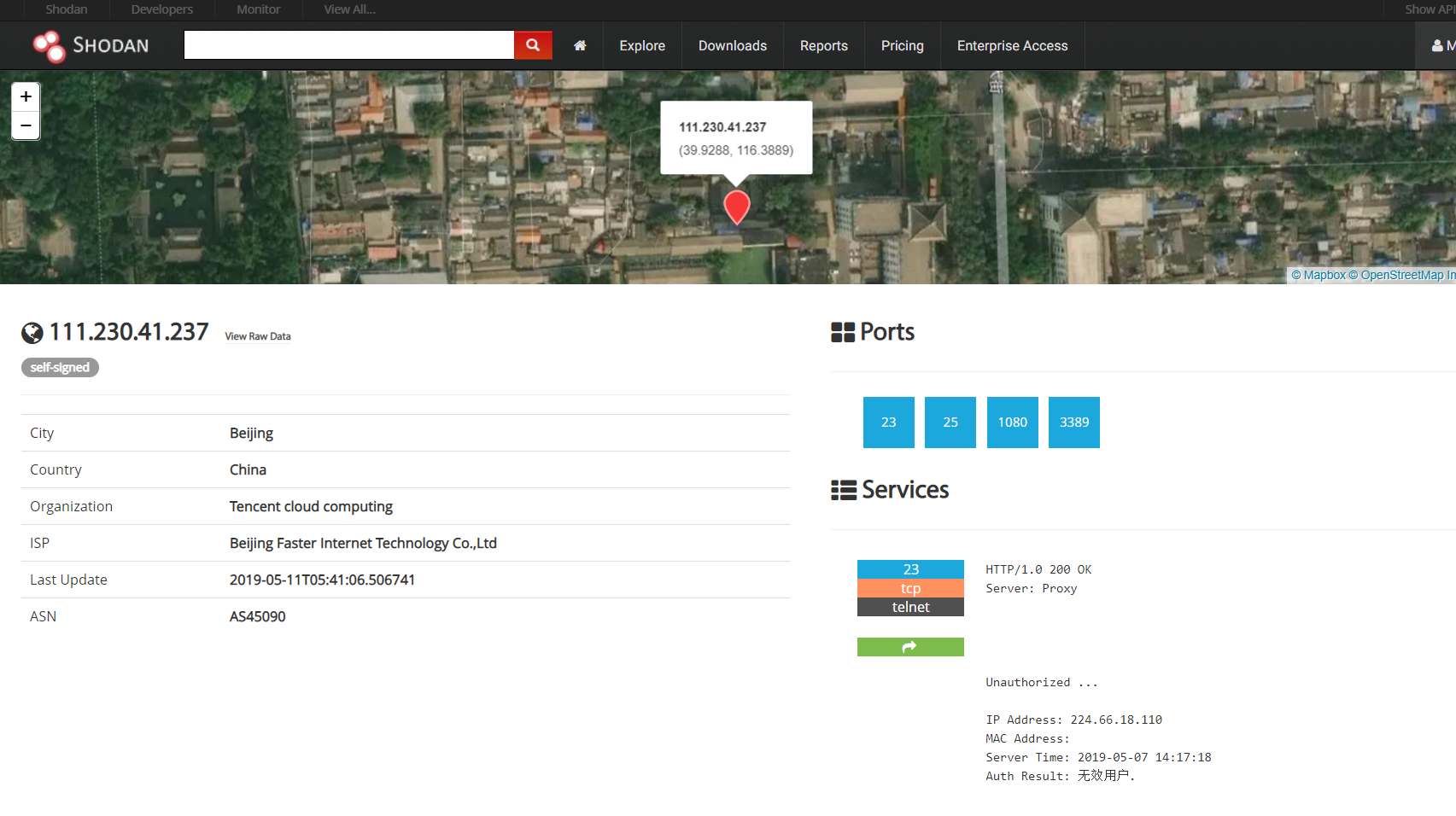
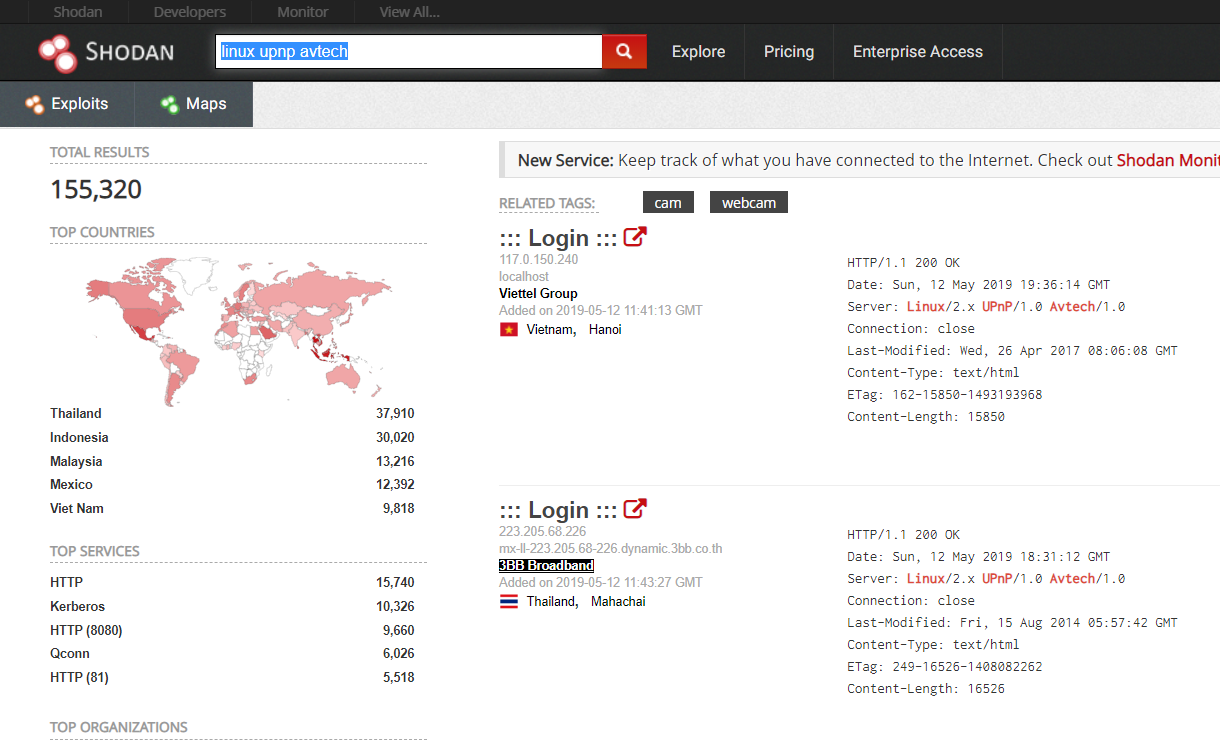
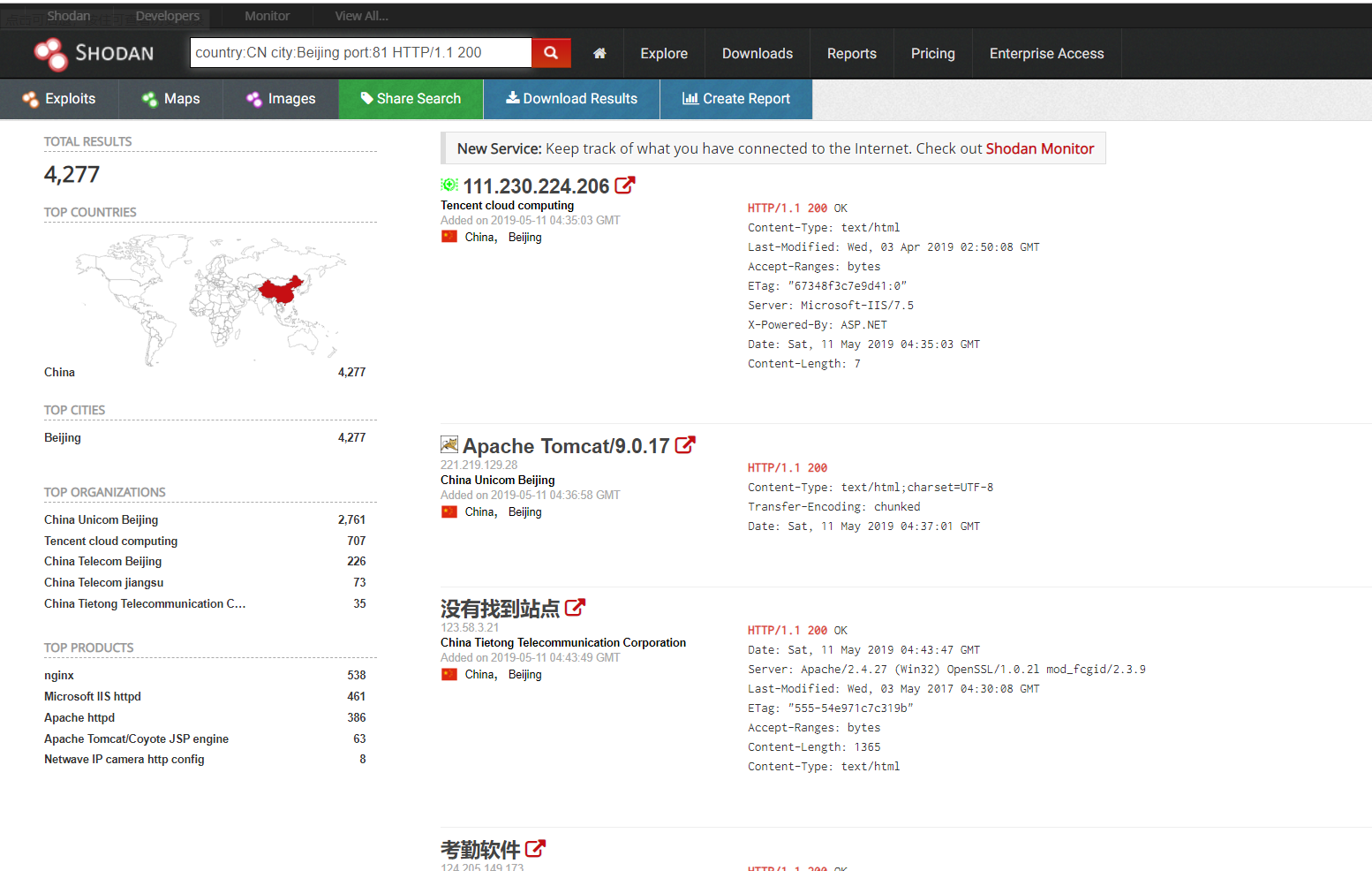 SHODAN可以说是一个很可怕的引擎,从上面这些就可以看到大量的全球范围内的设备信息,通过指定查询一些城市国家名、系统的版本信息、域名、开放端口等等信息,如果牵扯到没有设防的,就是很不安全的行为。
SHODAN可以说是一个很可怕的引擎,从上面这些就可以看到大量的全球范围内的设备信息,通过指定查询一些城市国家名、系统的版本信息、域名、开放端口等等信息,如果牵扯到没有设防的,就是很不安全的行为。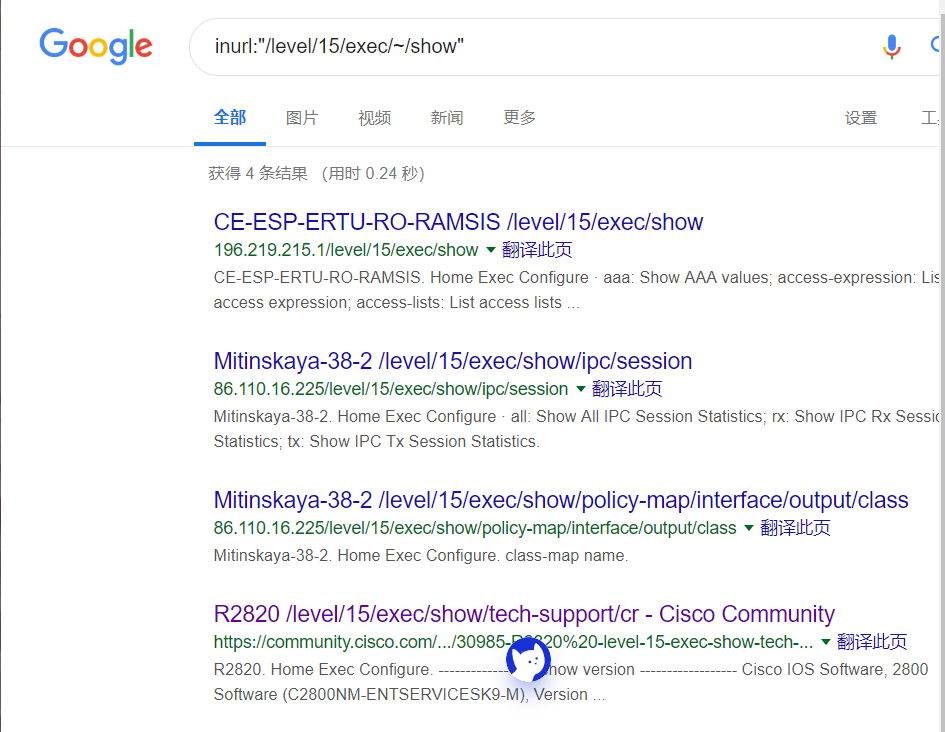
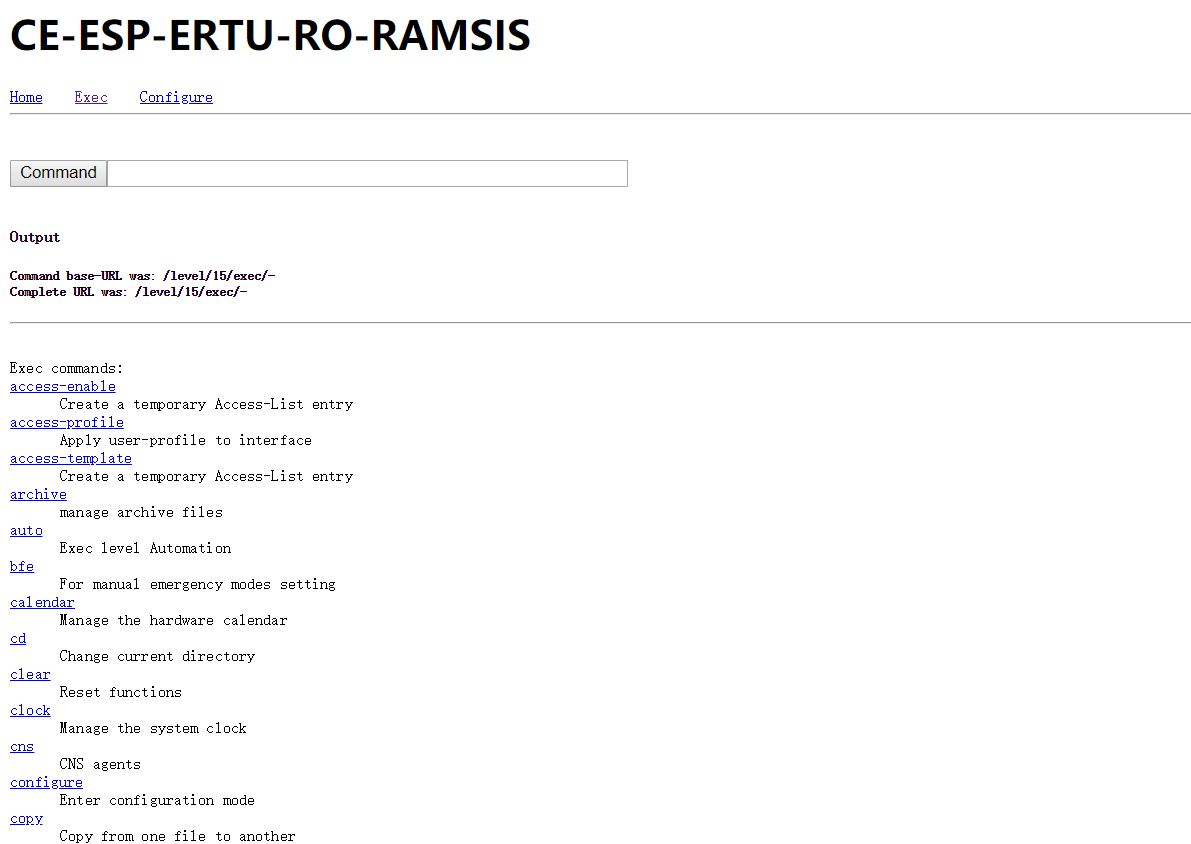 没太了解cisco的设备,不过这里是可以执行指令的,自己输入或者点击下面的指令都可以。
没太了解cisco的设备,不过这里是可以执行指令的,自己输入或者点击下面的指令都可以。 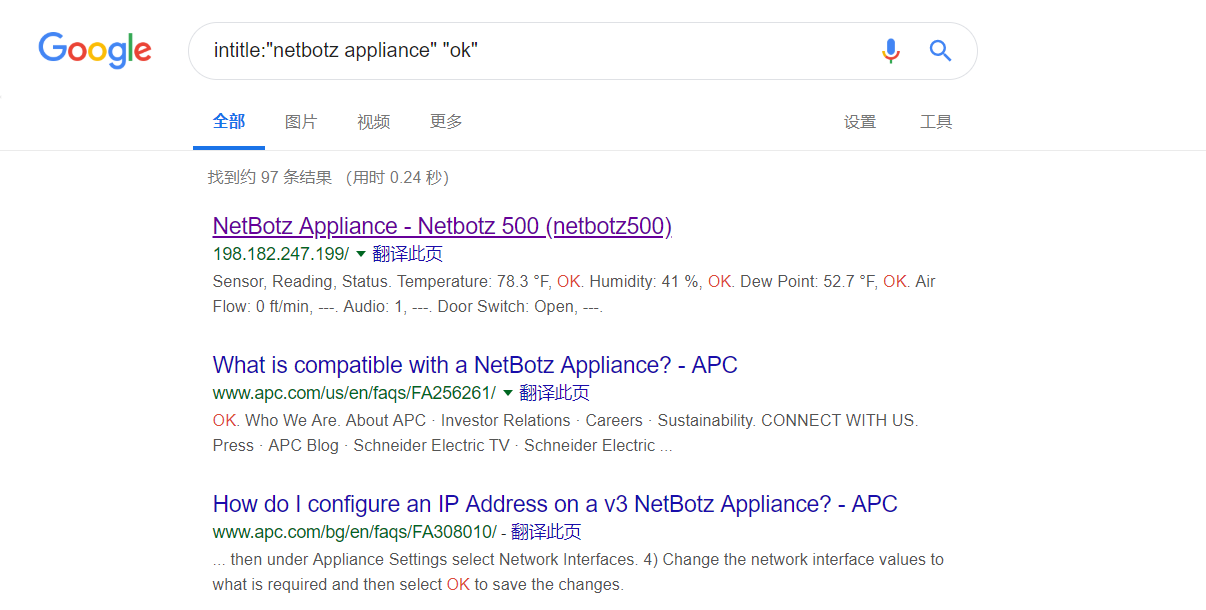 可以看到最上面的那个就是了。进去看一下(滑稽):
可以看到最上面的那个就是了。进去看一下(滑稽): 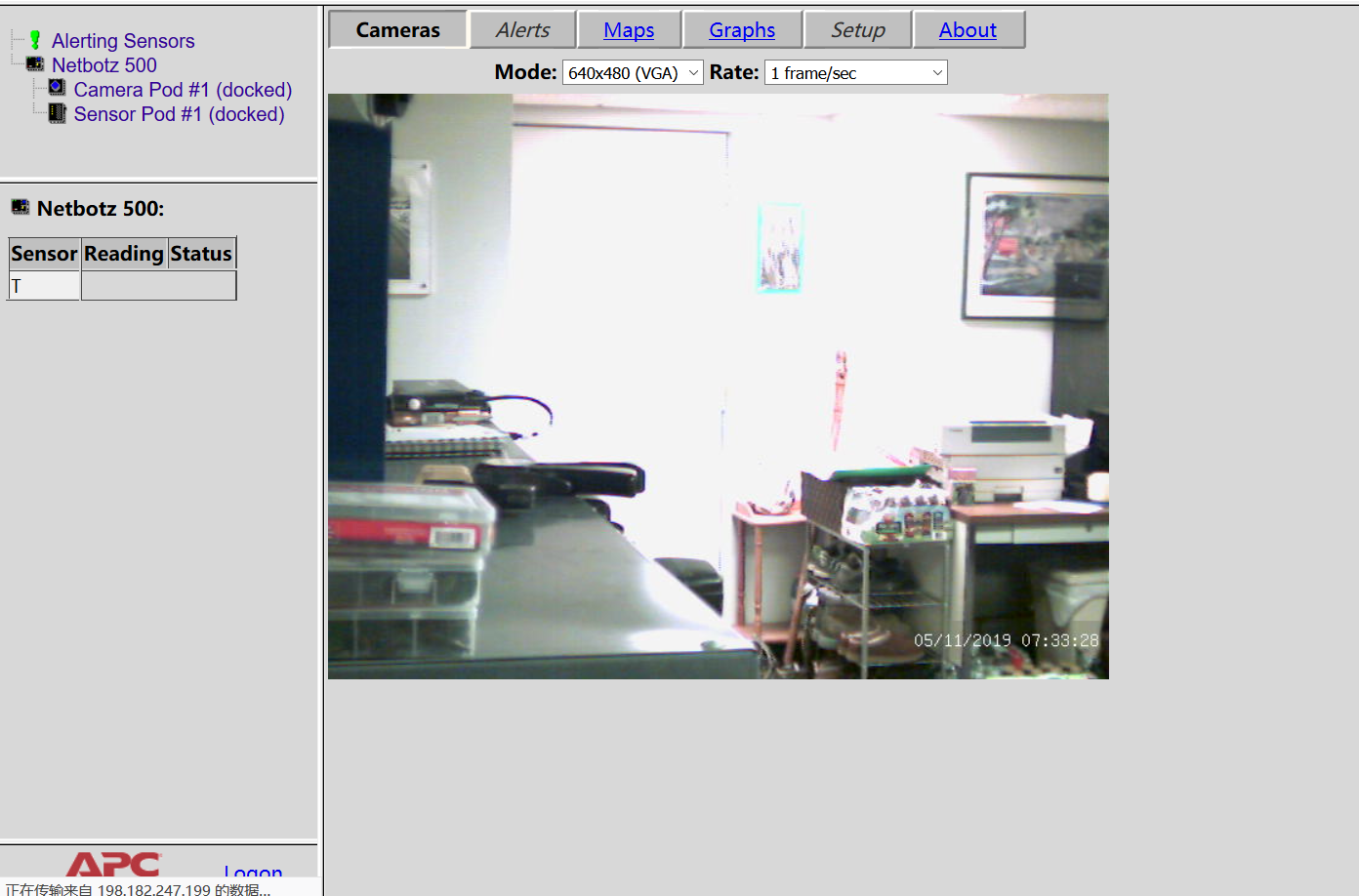 可以看到很多的如温度、湿度等的信息(这是。。卧室???)
可以看到很多的如温度、湿度等的信息(这是。。卧室???)